VAD Emotion Control in Visual Art Captioning via Disentangled Multimodal Representation
Ryo Ueda, Hiromi Narimatsu, Yusuke Miyao and Shiro Kumano, in Proc. International Conference on Affective Computing and Intelligent Interaction (ACII 2024), pp. 134-141, 2024.
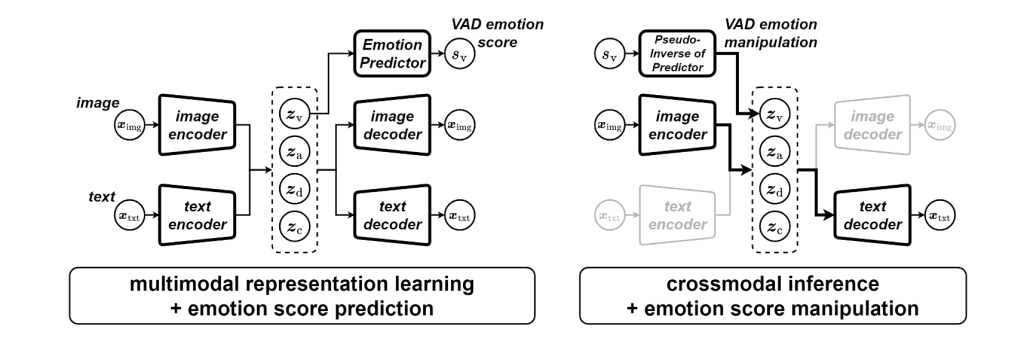
Art evokes distinct affective responses, leading to the generation of emotional verbal expressions in response to visual stimuli like visual art images. While previous research has addressed controlling linguistic impressions in terms of basic emotion categories, less attention has been given to their continuous, dimensional nature. This paper aims to continuously modulate emotions across valence, arousal, and dominance (VAD) dimensions by employing multimodal representation learning (MMRL) and crossmodal inference. We utilize a multimodal variational autoencoder for MMRL, encoding visual and textual stimuli into a continuous joint vector representation. We then auxiliarily tune this representation to explicitly include the VAD dimensions in a disentangled manner. This enables nuanced emotional control in image captioning, where visual inputs are converted into vectors and then into text. Trained on the ArtEmis dataset, which includes emotion-evoking captions for visual art, as well as additional datasets annotated with VAD scores for either text or visual art, our model demonstrates that manipulating VAD intensities in the vector representation results in continuous caption variations, reflecting the intended emotional changes.
This is a collaborative work with Miyao Lab. at the University of Tokyo.